Migrating from C to C++: A Case Study
by
Jack W Reeves
©C++ Report - 1995
Introduction
Those of us who work with C++ on a regular basis sometimes forget that C++ is not yet the de-facto standard language for commercial software development. Just recently, a friend of mind remarked that C++ in general, and class libraries like MacApp and Microsoft's Foundation Classes in particular, seemed like an excellent way to rapidly develop working prototypes of user interface code. On the other hand, he felt that no commercial applications would be delivered in C++ because the overhead was too large. "What overhead?" I demanded.
From October 1990 until September 1992, I was involved in a major software development effort. This project started out in C, but ended as a C++ project a year and a half later . Not all of the code was rewritten along the way -- only about half. None of the rewritten code was specifically changed to make it C++. Yet the final design depended upon several hierarchical class libraries and made critical use of polymorphism. The final point -- all of this code is part of a Macintosh device driver. This driver, in turn, is used extensively by several applications that have some stringent responsiveness requirements. The applications themselves are all written in C++ also. Too much overhead? Not in this case.
Thanks to a combination of persistence on the part of the C++ fans on the project (initially just myself), a willingness of certain other members of the project to be convinced of C++'s benefits, some enlightened management, and quite a bit of just plain luck, the project became almost a textbook example of how to successfully migrate from C to C++. Nevertheless, there were several lessons learned in the process that might be of interest to those faced with similar situations.
Brief MDIS Overview
MDIS (Medical Diagnostic Imaging System) is a joint US Army and Air Force contract to develop a film-less radiology system for military hospitals. MDIS is an example of what is called PACS (Picture Archiving and Communications System).
The basic premises behind MDIS is that radiological images are captured in digital form instead of being generated on film. The images are then displayed on computer workstations (instead of traditional light boxes) for reading by radiologist and review by other physicians. The images are retained on optical media for comparison or if review is necessary in the future.
The government wanted MDIS to be constructed from inexpensive off-the-shelf hardware and software components. Naturally, they also wanted it to be able to do things that inexpensive off-the-shelf systems were never intended to be able to do. While this is an article about C++, not about MDIS, a brief understanding of some of the aspects of MDIS will make the rest of the article more meaningful.
X-ray film is a very high resolution, high contrast media. Digitizing these images in such a way that the information content remains suitable for a radiologist to be able to properly do his/her job takes a lot of data. A typical digital chest x-ray will contain 10-15 megabytes of pixel data, depending upon how it is digitized. More sophisticated imaging techniques such as MR (Magnetic Resonance) and CT (Computed Tomagrphy) can double or triple that. The radiology department of a large hospital facility can easily generate 20 - 50 Gigabytes of image data every day.
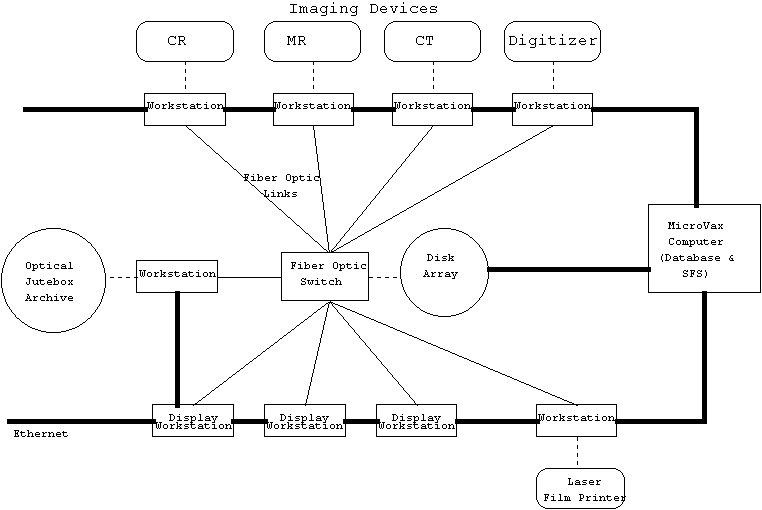
MDIS required on-line storage of all current imagery related to a patient for as long as the patient was in the hospital (average 3 days). On-line imagery had to be displayable on any workstation in the hospital within 5 seconds for the first image in a study, with other images being available within 2 seconds per image. All imagery had to be retained off-line for a minimum of 20 years, preferably for as long as the patient lived, for comparison with later imagery. It does not take a lot of arithmetic to figure out that the data storage capacities, access rates, and transmission rates for this type of system are not something usually handled by the local Computerland. Figure 1 shows a rough diagram of a typical MDIS system. Generic terms have been substituted for the proprietary names of the actual hardware.
The MDIS contract was to be awarded primarily on the basis of a set of benchmark tests run against a demonstration system that the different outfits bidding on MDIS were to construct at their respective facilities. The government was serious about MDIS being constructed largely from COTS (commercial off-the-shelf) components. They wanted to see it before they bought it. They recognized that what they were requesting did not already exist, so prospective bidders were given time to put together their prototype systems.
It is at this point that this story actually begins.
Historical sequences
In the spring of 1991, a LORAL Aerospace and Siemens Gamasonics team had developed a proposed MDIS architecture along the lines of that shown in Figure 1. The system was to use Macintosh computers as workstations running already existing software (called Litebox) developed by Siemens for displaying and reviewing radiology images. To provide the massive storage capacity and access rates, LORAL contributed a commercial version of a disk array they had built for another of their aerospace customers. All this was existing hardware and software with a proven track record -- just what the government wanted.
At this point, however, things got a little tricky. The disk array used an Ethernet interface running TCP/IP for commands and status responses. The image data went in and out via a high speed parallel interface, not over the Ethernet. Each disk array could support at most about a dozen workstations because of limitations on the number of parallel interface cards that could be attached to its back plane. Clearly, something else would have to be used to support several hundred workstations scattered about a large hospital. Furthermore, all the existing hardware and software for supporting the disk array was based on MicroVax workstations, not Macintoshs.
The proposal added a fiber optic network between the disk array and the workstations. In order to keep performance up, the fiber optic network used a very minimal protocol. A fiber optic switch was installed next to the disk array to allow the limited number of parallel interfaces to support a much greater number of fiber optic interfaces. On the Macintosh workstations, a custom Nubus interface card was specified to provide the fiber optic interface. I was part of the team brought together to build the software necessary to allow the Macintosh workstations to be able to read and write imagery from the central disk array.
The basic requirements were pretty simple on the surface. Siemens wanted to make the fewest possible changes to their Litebox software. They insisted that the disk array interface should be integrated into the Macintosh system software so that it would appear just like any other shared disk volume.
This was the goal, but naturally there were complications. The reality was that the disk array itself was suitable only for storing imagery. It had a physical blocksize of 16Kb with an optimal cluster size of 4Mb. The TCP/IP control interface and the firmware behind it were very rudimentary. There was no file system, no catalog, no file locking mechanism, etc., simply the ability to read and write raw data blocks. Rather than attempt to enhance the disk array firmware to make it appear as a shared volume, it was decided to do everything external to it.
A central catalog program was designed to run on a MicroVax workstation. It provided the mapping between file names and physical blocks on the disk array. It also maintained the allocation map for the array. A TCP/IP interface allowed the workstations to use the central catalog program (referred to as the SFS (Shared File System)). It was decided that the SFS would not command the disk array directly at any time. The workstations would query the SFS for the necessary information, and then command the disk array directly.
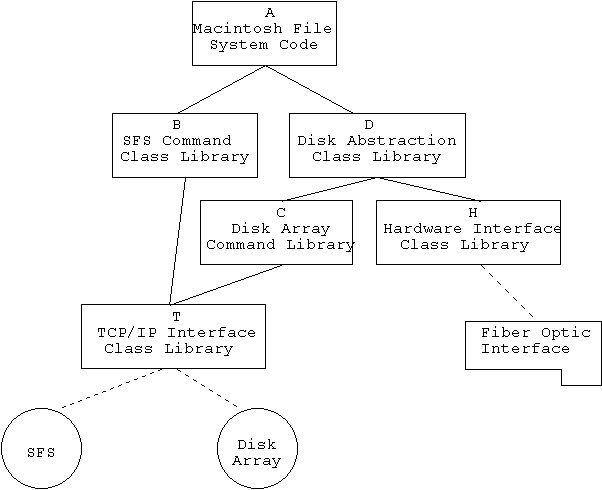
On the workstation then, the software broke (fairly cleanly) into 4 components:
- A. The glue code which provided an interface equivalent to the Macintosh file system interface. This code had to provide the same functions as the Macintosh file manager (at least those used by the Siemens software). This included the typical functions of Open, Close, Read, and Write, plus a few atypical ones.
- B. The software to interface to the SFS. This would issue typical commands such as Open, Close, Allocate, and Delete using the TCP/IP link. This software was responsible for establishing the TCP/IP link when the Macintosh booted, and gracefully closing it when the system shut down.
- C. The software that interfaced to the disk array over the TCP/IP link to send the low level Input and Output commands to the disk array. Like the SFS software, this component had to establish a TCP connection upon initialization, and break it when the system shutdown.
- D. The fiber optic hardware interface software. This software provided a level of abstraction for the hardware. It hid the details of the register layout and command structure. Since the hardware design was derived from another application for expediencies sake, there were some idiosyncrasies in the hardware that this software was suppose to hide. At the lowest level, this software set up the registers on the board, started the transfer, monitored its progress, and reported error conditions to higher levels.
A quick look at the list above shows some commonalty in parts B and C. Since all that either component apparently does is build a command and send it out over a TCP connection, it was decided to combine these two into a single library. I'll call it BC. Figure 2 shows a block diagram of the relationships between the components of the system, which was now called the EFS (Extended File System).
All of this software was to be written in C. I was assigned to do the hardware interface library, part D. At this point I will confess that I hate C. Well maybe hate is too strong a term -- I despise C. At that point in time I considered myself a decent C programmer, actually better than quite a few I had met, but C was not my favorite language. I had recently come from the world of Ada. I had seen systems of 1 million+ lines of code go together and work the first time they were linked. They did not work correctly, but neither did they abort with the typical memory dump caused when someone had passed a value where a reference was expected. I was a real fan of strong type checking. I was also a fan of object oriented design. I knew C++, but more in an academic sense than from real experience.
The project had one C++ compiler amongst the development systems. I installed it on my system and vowed that I would write C code in C++. That is precisely what I did. I wrote the library and compiled it with C++. When it came time to deliver versions for integration and testing I would recompile the library using the C compiler and clean up anything that it did not like.
Lesson Learned #1 -- C++ can be used just fine as a "better C". Just using C++ as a better C provides some distinct advantages right off the bat. One advantage is the C++ style function prototypes. While it is true that ANSI C allows the same style, my experience in porting quite a bit of ANSI C code to C++ indicates that unless forced into the habit, most C programmers do not use them. I have found that properly written C++ header files can go a long way towards giving C++ advantages similar to Ada where a program that links stands a good chance of actually running. Some of this advantage is lost when C++ libraries have to be written for commonalty with C programs. In the latter case, the C++ headers have to be declared 'extern "C"' which removes the name mangling that lets the linker catch a certain class of errors.
Another advantage of C++ is that it encourages proper treatment of pointers. C pretty much allows any kind of pointer to be assigned to a variable of any other pointer type. This can lead to some rather tricky errors. This is compounded by a typical C coding practice of using 'void*' to pass data structures to functions (a practice which also crops up in C++ programs and should be discouraged in both). C++ forces explicit casts when converting pointers to anything except 'void*'. This does not keep you from making silly mistakes, but it does tend to force you to make them deliberately instead of accidentally, and it documents them in the process. I take advantage of C++ by avoiding using void pointers as much as possible and not coding any explicit casts in my first version of a function. The compiler then points out all the places where I tried to use a pointer of the wrong type. I then fix each error individually. Sometimes an explicit cast is required, but before I write one I always make sure that I really need one. I catch a lot of errors this way, especially in argument lists to complex library functions that I do not use very often.
A particular combination of both the advantages mentioned above is when functions take a pointer to a callback function as an argument. In C the parameter is often declared 'void(*callback)()', i.e., a pointer to a function taking no parameters and returning nothing. This is the equivalent of declaring the parameter a 'void*'. The documentation then tells you to pass something like a "int (*)( int, char*, long, void*)". In C++ you can not get away with this. Try writing the explicit cast needed in this case. C++ will quickly convince you of the advantages of using typedefs to name your callback function prototypes and using the declared names in your parameter lists. The compiler will then guarantee that your users actually pass you function pointers of the right type.
Ideally, if you are using C++ as a better C everyone on the development team is using C++. This way you can drift into using simple C++ unique features without worrying about it. In the more likely case where some team members are still using straight C and you have to maintain strict compatibility with C there are a few things to watch out for: (a)You can not use reference parameters in functions which have to use C calling conventions. (b)Your header files should declare structure types using the form "typedef struct xxx {...} name;" instead of the common form of just "struct name {...};". This allows declarations to be coded in a C++ style (i.e., without the 'struct' keyword). (c)C++ allows variable declarations in places that C does not. This means declaring variables at the beginning of the function instead of wherever. End of Lesson Learned #1.
There was actually a lot of code written for the prototype MDIS system, not to mention several custom hardware designs that had to prototyped and tested. It all came together the weekend before Labor Day in 1991. The Army and Air Force were suitably impressed and awarded the MDIS contract to LORAL/Siemens later that year. Then came the problem of actually delivering the first system.
Not surprisingly, a great number of short cuts had been taken in developing the benchmark demonstration system. We had something that worked, and actually worked quite well, but there were numerous changes that we knew were necessary. Unfortunately, late in integration, a subtle but major flaw had been uncovered in the overall design as represented by Figure 2. Since this point is the basis of three of what I consider the most important lessons learned from the project I am going to dwell on it for awhile.
There is a race condition hidden in the design as shown in Figure 2. The functions in module BC are inherently asynchronous. In particular, commands to the disk array are sent out as messages, then the data must be transferred over the fiber optic interface, and then a response message comes back. Module BC was thus coded to be asynchronous, even though the commands to the SFS could have been treated as synchronous since the workstation must wait for a response from the SFS before it can issue any commands to the disk array. Module D can also be considered asynchronous in nature. The interface card is set up and then activated. Since it acts as a bus master for performance reasons, the software does nothing but wait for it to finish.
Because there did not seem any point in allowing the higher level functions to try to do anything while the interface card was pumping data, I built the hardware interface library around a synchronous abstraction -- a function call to the interface would not return until the transfer was complete. This meant that the call to module BC to command the disk array had to be made before calling module D. This made perfectly good sense when sending data to the disk array. On the other hand, it created a race condition when reading data from the disk array. You might assume (like I did) that this is a race condition that a Macintosh should never loose. After all, a Mac does not have a pre-emptive multitasking operating system to steal time. Go write on the board 10,000 times "I will never assuming anything about a race condition except that Murphy's law will apply."
Experienced network types will have already spotted the flaw in the above assumption. TCP is a reliable connection service. While module BC was coded for asynchronous use with respect to the response messages, the actual command messages were sent synchronously. This meant that the BC function would not return to A until the TCP acknowledgment was received. Put a little load on the Ethernet and it became all too possible for the disk array to have processed its' command and be pushing data out onto the floor before the workstation had processed the acknowledgment and been able to set up the hardware to receive the data.
Changing module BC to be asynchronous with respect to TCP and not wait for the acknowledgement allowed the software to work reliably when receiving data from the disk array, but created exactly the opposite problem when sending data -- now it was possible for the workstation to start sending data before the disk array had processed the command to receive it. This was attacked by putting delays into module A when sending data to allow the disk array to get ready. To me, these were kludges that indicated the design was wrong.
My punishment was having to go to my boss and grovel for permission to basically redo the entire design of the EFS. This was at a time when he was facing a totally impossible schedule to finish things that still had to be done. It would be an understatement to say he was not predisposed to rewrite something that was basically working.
I will add at this point that the problem was exasperated enormously by the fact that there was no error checking on the fiber optic link. None, zero, zilch. There was suppose to have been, but a problem getting integrated circuits of the proper speed rating had caused it to be eliminated from the design. As I said, some short cuts had been taken. They came back to haunt us. The only error the software could detect was when more than an entire 16Kbyte block was skipped. Then the hardware would hang up waiting for the last block and the software would time-out and return an error. If the actual transfer got into the last block, then the hardware would simply clock garbage out of the buffer until it thought it was done. In that case, failure was detected by the user when a totally scrambled image appeared.
I think the idea of having end users do our error detection probably swayed my boss quite a bit. In one of those fortuitous accidents, I sweetened the deal by suggesting that we rewrite the EFS in C++. The reason he liked this idea was that LORAL, like any big defense software developer, had EXTENSIVE documentation requirements, coding standards, and QA procedures for software. Once the MDIS contract was officially awarded, this was all about to come into play, whether it made any sense or not. It turned out that there were standards for things like Ada, FORTRAN, Jovial, and C, but not for C++. By coding in C++ instead of C, we could write our own procedures instead of being forced to use the companies pre-existing ones. Thus turn the wheels of progress.
I convinced my software teammates of the necessity of redoing EFS' design. I also convinced them of the advantages of doing it in C++. We convinced the boss. Then we got to do it.
My partner in this effort was not actually opposed to using C++, he was just worried about how much effort it was going to take to learn it. I argued that he did not have to really learn anything. I showed him my existing C++ code. It looked just like C. I was going to build some class libraries, but I showed him that a user defined type could be used exactly like an existing type with the only addition being the new syntax for calling member functions. He was willing to give it a try.
It took approximately half a day before his willingness turned into enthusiastic support. Running his existing code through the C++ compiler turned up several pointer conversion anomalies that he was disgusted had not been caught by the C compiler. He never looked back. From that point on, EFS was entirely a C++ project.
The new design is shown in Figure 3. Module BC was separated into two separate class libraries. A third class library T was created to provide an abstraction of the TCP/IP driver. This was not really necessary, but it provided a good example of what a properly constructed abstraction could do. The constructor and destructor hid some grungy start-up and shutdown code. The Send and Receive functions likewise hid details of complex parameter lists.
The most important change was to redefine the abstraction represented by the hardware control library. This was changed to be an abstraction of the disk array itself. Actually, the functions provided did not change at all. Just as before, the basic functions were SendData (to the disk array), and RecvData (from the disk array). Now, however, the library controlled not just the fiber optic interface card, but via calls to the disk array command object C, the disk array itself. This allowed things to be done in the proper order, eliminating the race conditions. The abstraction thus presented by module D became a reliable black box.
Another class library was created to encapsulate the actual fiber optic hardware control software (module H). This abstraction represented the hardware board itself. The member functions were almost a straight cut and paste of several internal utility functions used by the first version of the D library. Initially, this was just part of the process of converting the project from C to C++ and generally cleaning up the design wherever we could. As I will discuss below, this was one of those occasional cases where a small attempt to do something right pays big dividends latter.
The software went together much easier this time. Not only did we have the experiences of version 1 to build upon, but I think we all agreed that the overall software design was better.
Lesson Learned #2 -- Switching to C++ will not automatically improve your design. Most of the time this is phrased the other way around as in : "To gain the full advantages of C++ you have to change design methodologies as well as change programming languages." I think this needs some perspective. For example: you do not have to live in the high country where it snows 9 months out of 12 to justify owning a 4 wheel drive sport utility vehicle. Those people who do live in the high country find them indispensable. The rest of us find them useful enough on ordinary city streets and they make our occasional journeys into the high country a whole lot easier, safer and more fun. Likewise with C++. It works fine as an ordinary procedural language, and it makes occasional excursions into the realm of Object Oriented Design a whole lot easier, safer and more fun. It probably makes more sense to first switch to C++ and then to try object oriented design than to try to do both at the same time. On MDIS, I first started using C++ as a better C. Then while everyone else was doing that, I moved on to defining class libraries that others could use in their ordinary structured designs. In fact, parts of MDIS, the top layer module A in particular, did not lend itself to an object oriented design.
Lesson Learned #3 -- Using Object Oriented Design will not automatically improve your design. Object oriented methods are not a panacea. The original EFS design attempted to be object oriented. The original hardware control module D could have been implemented as a class library. It would have made a good class library, but it represented a bad abstraction. On the one hand, it was too abstract to represent the hardware directly. On the other hand, it did not represent a complete abstraction of the entire disk array control path. Hindsight seems obvious now, but at the time, the design went through several reviews by numerous different groups, and none of them spotted either the inherent race condition, or the weakness of the abstraction.
To me, this was the most important lesson that came out of the MDIS project -- good design is still an art, and object oriented design is no different. You can do what appears to be good object oriented design, and still have weak design. Nevertheless, object oriented designs are an improvement and one way to ease into OOD is to convert existing libraries to C++ class libraries or build C++ classes that interface to existing libraries. This often reveals ways to improve the information hiding and data abstraction.
Lesson Learned #4 -- There is no substitute for being able to take lessons learned and go back and do it over. This should be obvious, but bears repeating because it seems that all the academic work on software engineering methods ignore this obvious truth. Errors will slip through even the best review cycles; experience will indicate improvements; getting it completely right the first time is pie in the sky.
End of Lessons Learned #2-4.
After the first MDIS system was delivered at Madigan Army Medical Center, a series of enhancements in the system design required corresponding changes in the EFS software. These changes in turn revealed the overwhelming superiority of the object oriented design as implemented in C++.
The first change came up even before the Madigan installation was complete. The original MDIS design called for dual Ethernet backbones for reliability (this is not shown on Figure 1). All of the major components in the system, including the disk array, were configured with dual Ethernet interfaces. Workstations were attached to one or the other of the Ethernets. Bridges were strategically placed in the network to make it possible to bypass a break on one of the backbones.
In the initial version of EFS, a configuration file on a workstation would set the TCP/IP addresses that the workstation used to connect to the SFS and the disk array. Changing to the alternate required a manual reconfiguration. The systems engineers wanted the changeover made automatic, and more importantly, they wanted it to be able to happen in the middle of an operation. No problem!
Class library T abstracted the TCP/IP connection. It was enhanced to support a primary and an alternate address. If it discovered a connection had failed, it attempted to reestablish a connection using the alternate address before indicating an error. None of the code which actually used library T had to be changed at all. Abstraction started to pay off.
Next came the redesign of the fiber optic interface card. This was an obviously necessary step. The systems engineering group assured us software engineers that the register level interface to the hardware would remain the same. We did not bother to dispute them, instead we went off and added polymorphism to the design. The one day of effort creating class library H now paid itself back. I created a base class for the interface card. Class H' now had a subclass H1 which represented the first version of the card. Class H2 was designated to represent version 2 of the card. Common utility functions that did not address the card directly were moved to the base class. Class D was changed to refer to the hardware polymorphically.
When the design review for the new card was held a couple of months later, no one was surprised to discover that the hardware engineers had made only a token attempt to maintain compatibility with the first version of the card. My boss did a wonderful job of simulating indignation, frustration, and even anger. I had a hard time keeping from laughing. Integration testing of the new cards was actually a pleasant experience for me. All of the problems were hardware problems. Once the hardware engineers declared that they had working prototypes, it was quite literally less than an hour before we had a version of the EFS that worked with the new cards. This was because not one line of code that actually referenced the hardware interface had to be changed. None of the existing hardware library had to be changed, either. The only change to existing code was in the initialization section where an object of type H2 had to be created.
As an added benefit, the new EFS version would work with either version of the card. This made the job of upgrading existing installations much easier since the hardware upgrade did not have to be coordinated with the software upgrage. A blanket software upgrade could be done and then incremental hardware upgrades could follow as manufacturing ramped up.
A third problem came up during the same time as the interface was being redesigned. The disk array has an option whereby data can be passed directly from an input port to an output port. This allows disk arrays to be daisy chained together to increase storage capacity. Obviously, it complicates the control problem considerably. We were asked to enhance the system to support this capability.
I will not go into the enhancements to the SFS that were necessary to support this. For the EFS, there was some discussion of where to incorporate the changes. It was decided that the abstraction represented by module D would be enhanced so that it modeled the entire disk cluster. The case of a single disk array would become just a special case of a disk cluster. This way the abstraction remained clean. Fairly significant changes were made to certain parts of D. Now, in addition to calling upon both modules C and H, it also had to use commands from module B. Some changes were necessary in A, but these were extremely minor.
Finally, with MDIS looking like it might become a commercial success as well as a contractual one, LORAL decided to do an upgrade of the disk array design. MDIS had stressed the original design in several unexpected ways. Naturally, the new design would incorporate improvements that were incompatible with the old version. Once again, systems engineering assured us that it would never be necessary to support both old and new disk arrays in the same configuration. I don't think anyone paid any attention to them.
A base class for library C was created, with two subclasses representing the old and the new disk array design. I left the project at about this point, but I assume that bringing the new disk array on-line was similar to the upgrades for the fiber optic interface. Oh yeah, just before I left, word came down that systems engineering had determined that it might be necessary after all to support both versions of the disk array simultaneously at a site. My boss promptly demanded an additional three months for software development and integration to be able to accommodate this new requirement.
Lessons Learned #5 -- Do not rush into inheritance and polymorphic designs. One thing a lot of new object oriented designers do (I did myself) is to jump in and start creating base classes and subclasses. With all the new capabilities at your disposal, it is easy to forget that a lot of useful programming can be done with only basic abstraction. Do not hesitate to take advantage of that usefulness. Even when certain aspects of a design seem to cry out for inheritance, be leery if this is the first true object oriented design that is being attempted by the project team. Good OOD requires experience. Do not try to rush it.
Inheritance and polymorphism open a whole set of new problems. My experience indicates that it is best to try to create good abstractions of the existing objects first. Then, as it becomes necessary, an abstraction can be turned into a base class with the necessary subclasses representing the different categories of the abstraction.
A good counter example is provided by the TCP/IP abstraction (module T). As noted above, early in the object oriented development it was enhanced to provide support for dual connections and automatic failover. These changes were made directly to the library. After the fact, we went back and created a base class which represented the original abstraction, and a subclass which contained the fail-over enhancements.
This did not seem quite right, however. By this point I had become quite sensitive to whether an abstraction felt right or not. It could be argued that this arrangement made sense. It could be argued that treating both classes as subclasses of some base class which provided an abstraction of a "connection" made sense. I'll leave such arguments as an exercise for the reader. My feeling was that this structure did not make sense for EFS.
EFS used the dual connection object exclusively. The class itself provided the abstraction of a single connection, so there seemed little point in the base class. At the same time, the base class obviously provided a useful abstraction in its own right. The question was simply what relationship should they have to each other. I broke the inheritance and turned the two TCP/IP connection classes into separate entities. The dual connection class was re- implemented in terms of two objects of the other class. This greatly simplified its implementation, and retained the advantages of code reuse that inheritance would have provided. In other words, I switched from using an inheritance structure to using a more common aggregation structure. To this day I can not argue that this is a better organization than one using inheritance, but it feels better to me.
Lesson Learned #6 -- You do not have to send anyone to C++ or OOD class. This is one of the really GREAT advantages of C++. C programmers can become C++ programmers over time with just experience and a few good references. It does help to have at least one experienced C++/OOD guru on the project to help others past hurdles and keep frustration levels from getting too high until everyone comes up to speed.
Lesson Learned #7 -- Do not expect C++ to gain you much right at first. As note in Lesson #1, it will gain you something, but the gains are small and of the indirect type, i.e., fewer errors to find later. Initially C++ will just be C with some new statements. In fact, initially C++ may seem to set you back as the more stringent type checking forces programmers to clean up supposedly working code (I'll bet long odds at least one bug is discovered in the process). Also, if you try to move too rapidly into using OOD and the corresponding features of C++, you can get caught in a quagmire of little understood errors (see the second part of Lesson #6). The key is to take it slow and let the advantages build up.
Lesson Learned #8 -- Expect that the combination of C++ and object oriented design will pay big dividends in the long run. These dividends will include more robust designs that are easier to maintain; easier integration; easier testing; and ultimately more reliable and maintainable systems.
Lesson Learned #9 (maybe) -- Depending on your organization and what you are trying to build, C++ might necessitate some changes to your software QA procedures. Inheritance and polymorphism make it possible to add tremendous amounts of new functionality to existing software without changing a line of code. If the new subclass correctly implements the abstraction required by the base class it should be possible to just re-link and go. How do we QA such upgrades? The obvious answer is to regression test everything. This is what we did on MDIS, but it seems to loose some of the advantage of the abstraction if we continually have to re-test code that is not changing. This is a problem I have no answer to, just be aware of it.
Lesson Learned #10 -- Do not be surprised if C++ designs seem to run more efficiently than older C designs. Certainly they should run at least as well. Since the topic of efficiency is what started this article, it seems appropriate to end with it. Efficiency of C++ seems to be a real stumbling block for both old line C programmers and managers. There seems to be an unconscious feeling that C++ designs might be better, but they will not run as efficiently as plain C. My experience says that C++ code tends to be more efficient than C.
I think part of this is the reuse factor. When class libraries are used, more reuse takes place. This not only reduces the incidence of common code spread throughout a project, but it actually improves the efficiency of the reused code because many different programmers take an interest in seeing that it is efficient. The other reason is more subtle. I call it the "clutter" factor. Not only does reuse keep the same code from being scattered throughout a system, but it can actually reduce the amount of code that gets executed. Often times when code is duplicated in many places, part of that code is involved in recalculating intermediate values that do not change. These values are calculated in many different places because programmers do not want to clutter the global name space, or the parameter list, by including numerous simple values that are easy to calculate. An object on the other hand maintains state information. This can be anything at all. Once all the code for manipulating something comes together in one place, a lot of common values can be factored out, computed once and saved as part of the object. This may not create any noticeable difference in execution speed, but it doesn't hurt.
One thing is for sure. There was no noticeable change in the performance between the original C version of EFS and the C++ version. Whatever differences may have been introduced by the language change was totally in the noise level of the overall application performance specs. As always, algorithms probably make more difference than any thing else.
End of Lessons Learned #5-10.
Conclusion
In retrospect MDIS comes out looking like a good example of a textbook transition from C to C++ and from structure techniques to object oriented methods. To recapitulate:
1. Have a few members of the team start using C++ as a better C. Don't force it. Let those who actually want to learn C++ do so, let those who want to stay with C do that. At first, insist that everything written in C++ be reasonably compatible with C. In particular, do not let the C++ programmers get carried away with creating class libraries. This can be a problem if you have some C++ experts on your team since they will want to start creating class libraries and doing object oriented design right away. Assure them that the transition is under way and a little patience on their part will be rewarded.
2. After people get comfortable with stricter prototypes, being able to use such things as reference parameters, and comments that start with a '//', then introduce some classes where they make sense.
One way to do this is to obtain a third party class library and start using it. These libraries can provide useful utility classes which let people start using objects and member functions in their programming without immediately getting caught up in the details of actually creating classes. Once people start to see the advantages things go pretty quickly. Make sure you get source code. This provides examples and a starting point for writing your own class libraries.
Unfortunately, my own feeling is that many class libraries provide as many bad examples as good ones. A pet peeve of mine is the String class. Every library has them, and almost none of them work the way I think they should.
Also get some good books on C++. One of my favorites is C++ Components and Algorithms by Scott Robert Ladd (M&T Books). This book comes with a diskette that contains the source code from the book. This provides a basic class library with some very useful classes. I also like Ladd's philosophy about class library design (it matches my own, except in the case of class String). Another must have is The C++ Programming Language Second Edition by Bjarne Stroustrup (Addison-Wesley). Besides being the language reference manual for C++ this book is a very readable introduction to C++ programming at all levels. Two other books that I highly recommend are Effective C++: 50 Specific Ways to Improve Your Programs and Designs by Scott Myers (Addison-Wesley), and Advanced C++ Programming Style and Idioms by James O. Coplien (Addison-Wesley). The first is a veritable goldmine of information about subtle aspects of C++ class design. The latter is an excellant intermediate text on C++. The sidebar provides a partial list of various C++ books that have caught my attention. Any good technical bookstore will probably have many other texts on C++.
As well as using predefined classes, at this point you can consider writing some fairly simple ones of your own. Obvious candidates are hardware interfaces, encapsulating an interface to a particularly complex library, or abstracting certain data structures. It must be emphasized that nothing can substitute for experience in designing class libraries. Start small and build experience incrementally. My first class was a linked list. I have ended up using that class in practically every project I have written since. On MDIS, the TCP/IP library interface was one of the first classes defined. It was also one that paid dividends very rapidly.
3. After you have been using predefined classes, and have created several simple classes of your own, then your development team can start to consider more serious applications of object oriented design. Take a look at the big picture and start asking the questions : What are the objects in your system? Are there parts of the system that might usefully be combined into an abstraction? As you identify these larger classes, have the designated designers first do a complete definition of the class. Code the header file and do a design review on it. Always ask -- "what is the abstraction being presented here and does it make sense?" Be prepared to make some mistakes and have to redo some things. Be prepared to reject the object oriented approach altogether. Sometimes a purely functional decomposition is appropriate. There is no point in forcing such designs into an object oriented mold. With C++ you do not have to.
4. Finally, after creating a first cut object oriented design of your system, then look to see where inheritance and polymorphism can be used to enhance the robustness and future flexibility of the system.
Sidebar - Partial list of books on C++ and OOD
Advanced C++ Programming Style and Idioms - James O. Coplien (Addison-Wesley)
Applying C++ - Scott Robert Ladd (M&T Books)
C++ Components and Algorithms - Scott Robert Ladd (M&T Books)
C++ Primer Second Edition - Stanley B. Lippman (Addison-Wesley)
The C++ Programming Language - Bjarne Stroustrup (Addison-Wesley)
C++ Programming and Fundamental Concepts - Arther Anderson (Printice Hall)
C++ Programming Style - Tom Cargill (Addison-Wesley)
C++ Statagies and Tactics - Robert B. Murray (Addison-Wesley)
Some Object Oriented Design and Programming Books
Object-Oriented Analysis - Peter Coad / Edward Yourdon (Yourdon Press)
Object-Oriented Design - Peter Coad / Edward Yourdon (Yourdon Press)
Object-Oriented Programming - Peter Coad / Jill Nicola (Yourdon Press)
Object Oriented Modeling and Design - James Rumbaugh, et. al. (Printice-Hall)
Object Oriented Analysis and Design with Applications - Grady Booch (Benjamin Cummings)
Figure 1.
MDIS System Overfiew
Figure 2.
Initial EFS Design Structure
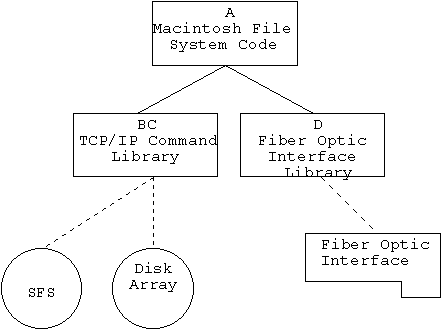
Figure 3.
EFS Design Structure V2