"The
(B)Leading Edge"
Wrapping up and looking ahead
by
Jack Reeves
©The C++ Report
Introduction
This column is going to be something of a transition. First, I want to wrap up the discussion of Indirect Visitor that I started two columns ago [1,2] and which has now gone on much longer than I intended. Then I want to step back and take a look at some of the my older columns and maybe make a few corrections or comments that seem justified now that they have had a chance to age somewhat. Finally, I'll provide a brief overview of what I plan to cover in the next year or so.
First allow me to apologize to those readers who have not read and do not have immediate access to the previous columns that I will be mentioning. While I would wish that every column stand on its own, sometimes that is difficult. In this case, it is virtually impossible. I will summarize the other columns as best I can, but there is no way I can present more than a sentence or two. To try and mitigate this situation somewhat, I have posted copies of all my past columns on my web site at www.bleading-edge.com.
Wrapping up Indirect Visitor
In [1] I presented a variation of the Visitor pattern (see Design Patterns [3]). That version of Visitor used the map<> template from the Standard C++ library to provide a simulation of a virtual function table. The map<> key was a type_info* obtained by using the typeid() operator. The value part of the map<> was a pointer to a visit function. As I noted in [1], that version was not as well received as I had expected. My coworkers worried about the overhead of the map<> class and felt that no matter how low it might be, it was obviously higher than the standard visitor class. The question was "why pay for the runtime overhead if you didn't have to?"
So I revised Indirect Visitor in [2] to use a vector<> instead of the map<>. In this case the index of the vector is a unique identifier for each class in the node hierarchy. The identifier is generated by a set_uid() function defined in the base class of the hierarchy. This scheme actually works very well, but there are a few idioms that I want to point out. All of these are applicable to either version.
First, suppose you wish to override a visitor function in a derived visitor to add some functionality, but then invoke the base class' version. In a normal derived class you would do something like
MyClass::foo()
{
// do something
inherited::foo();
}
[Note: the identifier inherited is a typedef for the base class' name. This idiom is described by Stroustrup in D&E [4] and I use it regularly]. Since the visit functions in Indirect Visitor are not member functions, a different form is required.
MyVisitor::Impl::visit_foo(Visitor& v, Object& o)
{
MyVisitor mv& = down_cast<MyVisitor&>(v);
// do something
mv.inherited::visit(o);
}
The unusual form of the call to visit() is required to prevent visit() from being invoked as a virtual function. Alternatively, you could write
MyVisitor::Impl::visit_foo(Visitor& v, Object& o)
{
// do something
VisitFunction f =
f(v, o);
}
Of course, this is exactly what the call to inherited::visit() does. The two things to avoid is looking up the function pointer directly as in
VisitFunction f = inherited::function_table()[Foo::UID];
This will return the function pointer for Foo in the base class's function table, but this could be a null pointer. You might as well let the look_up() function in Foo handle that check. The other problem is invoking the visit function virtually as in
MyVisitor::Impl::visit_foo(Visitor& v, Object& o)
{
MyVisitor& mv = down_cast<MyVisitor&>(v);
// do something
inherited& iv = mv;
iv.visit(o);
}
This is just a recursive call to MyVisitor::visit().
In this particular case, you want to make sure that a call to visit() is not a virtual call. In another case, you want to insure just the opposite. In my example (based on Meyers [5]) I imagined a hierarchy of outer space game objects. One of my GameObjects was a SpaceDock. As SpaceDock object contained a (possibly empty) collection of SpaceShip objects. It is easy to imagine that a standard PrintVisitor::visit_space_dock() function would print out some information about the SpaceDock itself, then iterate over the SpaceShip collection and visit each SpaceShip object in turn. A simple version might look like
PrintVisitor::Impl::visit_space_dock(Visitor& v,
GameObject& o)
{
PrintVisitor& pv = down_cast<PrintVisitor&>(v);
SpaceDock& sd = down_cast<SpaceDock&>(o);
pv._os << "Visiting Space Dock" << sd.name() << ‘\n’;
std::for_each(sd.list().begin(), sd.list().end(), pv);
}
In this case, the for_each() function invokes the visitors operator()() function, which in turn calls visit() as a virtual function. This way, someone can derive a new visitor from PrintVisitor, supply visit functions for various types of SpaceShips, but not have to override the SpaceDock visitor function. Now you see one of the reasons why I have my Visitor base class provide an operator()() function as well as visit().
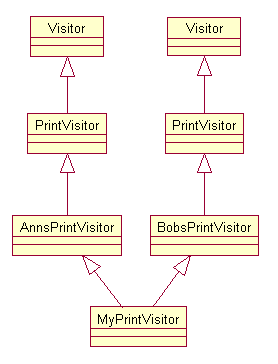
I wrapped up [2] with a slightly contrived example of how to do multiple inheritance with the Indirect Visitor. The resulting class tree is shown in figure 1. In testing this idea, I made an interesting discovery. MyPrintVisitor inherits from both AnnsPrintVisitor, and BobsPrintVisitor. Since neither Ann nor Bob declared PrintVisitor a virtual base class of their visitors, the resulting object of type MyPrintVisitor contains two copies of both PrintVisitor and Visitor. MyPrintVisitor overrides any function that is unique to either BobsPrintVisitor or AnnsPrintVisitor with a forwarding function. That function uses a dynamic_cast to recover a reference to MyPrintVisitor, and then invokes either Ann's or Bob's visitor as necessary. If a slot in the function table was identical in both Ann's and Bob's visitors, then I assumed that the function was a PrintVisitor function, and just left it alone in MyPrintVisitor's table.
When I tested this, I used a debugging version of PrintVisitor and ran into an interesting situation. In PrintVisitor visit function first tries to recover the PrintVisitor object reference. A typical snippet of code might look like
PrintVisitor::Impl::visit_asteroid(Visitor& v,
GameObject& o)
{
PrintVisitor& pv = down_cast<PrintVisitor&>(v);
As I described in my RTTI column [6], the down_cast template actually does a dynamic_cast during debugging, but switches to a static_cast for released libraries. In this case, the dynamic_cast of 'v' first recovers the underlying MyPrintVisitor object reference. It then attempts to convert that to a PrintVisitor reference, but since there are two PrintVisitor objects in a MyPrintVisitor, the cast is ambiguous and throws a bad_cast exception. Switching to a release version of PrintVisitor produced the results I expected. This is the first case I am aware of where a static_cast is the preferred over a dynamic_cast for functionality’s sake and not just for performance reasons.
Since it was concerns about the performance of the map<> based version of Indirect Visitor that led directly to the current version, I can not resist a brief look at the performance of Indirect Visitor compared to the standard Visitor. The standard visitor has the following overheads (assuming a do-nothing visit function):
virtual function call -- accept()
virtual function call -- visit_xxx()
return
return
In comparison the Indirect Visitor has these overheads
virtual function call -- visit()
function call -- function_table()
return
virtual function call -- look_up()
indexed table look up
test for null pointer
return
function call -- visit_xxx
return
return
On the assumption that a typical C++ implementation of a virtual function call is equivalent to an indexed table lookup followed by an ordinary function call, then the Indirect Visitor has 3 virtual function calls, a normal function call, and a null pointer test versus 2 virtual function calls for the standard Visitor pattern. Rounding things off, I would say that Indirect Visitor has about twice the overhead of the standard Visitor. Given any functionality at all in a typical visit function (and most of my visit functions do conversions from one data format to another), then I think it is safe to say that Indirect Visitor has overhead which is comparable to the standard Visitor pattern.
I discussed the advantages of Indirect Visitor in [1] and [2], but I also mentioned that there are some disadvantages to using Indirect Visitor. These can be summarized in one word: complexity. When building a specific visitor, the programmer has to do things that ordinarily are left up to the compiler. This is tedious, and can be error prone, and the compiler will not be able to catch your mistakes. For example, suppose you add a new class to the node hierarchy, and forget to include a definition of the class's UID in the class' implementation file. With a Standard C++ system, this will cause a link-time error. With Cfront, and those implementations which attempt to maintain compatibility with Cfront, the lack of a definition for a static member will go completely unnoticed. If you get the linker error and add the definition of UID, but do not initialize it using the set_uid() function, then the system will silently give your new node class a UID of 0. To help check against this type of error, I arranged for all UID's to begin with 1. If a system has correctly initialized all UID's, then the zero'th slot in the visitor function table with always be a null pointer. I check for this with an assert in the init() function.
There are a numerous other mistakes that can occur when setting up a visitor function table. Some of these you can test for, and some you can not. On my real version of Indirect Visitor, I created several test functions as static members of the Visitor base class. Besides the check for node UID initialized to zero, the one I use regularly checks to make sure that all non-null function pointers in a table are unique. This catches a certain type of editing error. Obviously, the dynamic_casts in the individual visit functions will also turn up certain types of errors, but this requires more extensive debugging. The obvious point is your testing should actually invoke every visit function in your table. You can no longer assume that just because you wrote it, that you can actually invoke it.
Overall, however, I have found that Indirect Visitors are not that hard to create and debug, and the flexibility is certainly appreciated. If you have actually studied the standard Visitor pattern in more than a casual manner, you may have a few questions about why I chose this approach. Some of the questions that I have asked myself include:
a. John Vlissides presents a "trapdoor" mechanism for the standard Visitor pattern in [7]. This allows a node hierarchy to be extended without having to recompile everything. Did I consider that mechanism? Yes, I did, but I consider the "trapdoor" a temporary means of adding one or two classes to an existing hierarchy until it is convenient to change the hierarchy and recompile all the libraries. The Indirect Visitor is a more general purpose mechanism, though it does take some work to set up correctly.
b. Did I consider the Acyclic Visitor pattern? The Acyclic Visitor is described by Dr. Martin in [8]. I must admit that I was not aware of the Acyclic Visitor until Dr. Martin and I were discussing Visitor's over a couple of beers in New York. I really like the Acyclic Visitor, and I find it fascinating that we have two variations of Visitor which address the same problem, but do so in totally different ways. Acyclic Visitor uses multiple inheritance and RTTI for its solution. As such, it is a lot easier to use since it depends upon standard features of the language. Nevertheless, I get the feeling that Acyclic Visitor is best suited for a different kind of problem than Indirect Visitor. I would recommend that developers have both variants (in fact, all the variants they can find) of Visitor in their toolkit, and use the one that seems most appropriate for the problem at hand.
c. Did I consider replacing my original map<> with a hash table? Ah, now this is the question. The simple answer is that I actually argued that if the log-n overhead of a map<> was too high, then a hashed_map<> was the logical replacement, but when it came time to actually replace map<> with something better, I didn't have a hash_map<> template lying around. If you think that is a rather weak excuse, so do I. I mention it just to make the point that just because something is not part of the Standard Library is no excuse for not having it available when you need it. There are several good implementations of hashed_map<> available, as well as numerous other useful class libraries, and if you do C++ development for a living, you owe it to yourself and your company to check them out. My real excuse is that at the time one of my platforms was still based on Cfront, and I had no idea whether the versions of hashed_map<> that I could get would work with Cfront. Furthermore, I didn't want to take the time to find out. That has changed, and in retrospect, I would argue that under most circumstances the best way to implement Indirect Visitor is by using a hashed_map<>.
One final note: the form of the look_up() function reminded me of what conceptually happens when you send a message to an object in a symbolic language. First the object's class is checked to see if it has a method that can handle the message. If not, then the object's immediate base class is checked. This lookup continues until either a method is found, or the root base class is reached without finding a message handler, in which case an exception occurs. I am a firm believer in the adage that if you want to program in a symbolic language, then use a symbolic language. Nevertheless, sometimes you can use the flexibility of a symbolic language, even though you are programming in C++. The Indirect Visitor provides a reasonable facsimile of that flexibility. The nodes in the hierarchy represent the classes in a symbolic language, and hold the data. The visitors represent the methods of the classes, with the data in the visitor objects being the parameters of the methods. This is hardly an easy to use pattern, but it does allow you to add new classes and new methods for those classes anywhere and at anytime without having to recompile the world.
Looking backward
Over the past couple of years, I have made a few mistakes that I would like to straighten out. Elsewhere in this magazine I have addressed my faux pa with the example program I put together to introduce my column on Low Overhead Class design [9], so I will not go into that here.
I was taken to task after my column on RTTI [6] about my conclusions regarding the performance of a dynamic_cast when implemented by a real compiler. I mentioned in the column that a compiler would certainly not be comparing strings as my home grown version had to do, but I did not think through how a compiler might actually implement dynamic_cast. The first point is that a compiler will probably not be using a linear search of base classes; it will probably use a hash table. Right off the bat this moves things into the realm of being a constant time operation. Much more to the point, it was pointed out to me that a compiler can reasonably assume that if one attempt has been made to dynamically cast type A to type B, then other attempts will likely occur. This means that it is worthwhile for the compiler to cache the results of a dynamic_cast. If this is done, and I am assured that good compilers do this, then effectively the performance of ANY dynamic_cast in a program can be considered amortized constant time. Naturally Order(1) is not the same as Order(0), but for all practical purposes, any dynamic_cast will have pretty much the same overhead as any other.
I have to mention that in spite of probably being a couple of orders of magnitude slower than a real version of dynamic_cast, the overhead of my home grown version is undetectable in practice. This leads to the conclusion that the correct use of RTTI will probably not add any noticeable performance penalty to an application. Just like virtual functions, concerns about the overhead of RTTI turn out to be unfounded in all but the rarest of circumstances. If my remarks in any way contributed to those groundless concerns, I hope I have corrected the situation.
One final little correction: in my column on moving to Standard C++ [10] I mentioned the typical practice of using forward declarations of classes such as ostream and string just so you could declare a reference or pointer. I pointed out that since these classes are not classes in the Standard library anymore, but rather are typedefs for complex templates, you can not be able to use the forward declarations any longer. What I did not mention is that the Standard Library provides a standard forward declaration for the iostream classes in header <iosfwd>. Unfortunately, there is no comparable header for string, but you could probably create your own.
My biggest mistake in that column [10] was predicting that Standard C++ compilers would be appearing Real Soon Now. At that time, the second Committee Draft of the Standard had been available since Nov 1996, and I thought that was pretty close to a finished standard. I must have been wrong, because even though the final draft of the Standard was approved in November 1997, I still do not see the flood of Standard compliant compilers that I expected.
Some vendors are making real efforts, however, and so I have hopes that we will see real ISO Standard C++ compilers and libraries by the end of 1998. Unfortunately, 1997 left me somewhat discouraged and cynical about the rate of progress on that front, so I am not making any bets one way or another.
Looking forward
While ISO Standard C++ compilers may be rather slow in appearing, I am fairly sure that they will eventually arrive. In the meantime, however, compilers are appearing which support more of the new features of the Standard. Also, more and more vendors are starting to ship versions of the Standard Library with their C++ compilers. As a result, I will make two predictions about what will happen as programmers start to use Standard C++ features and the Standard C++ library on a regular basis.
The first thing I predict is that people will find that it is easier to get their code correct. The Standard library provides numerous tools that make it easier to avoid many of the traditional sources of errors which ordinarily occur in writing C/C++ code. In fact, many people may have that sublime experience of creating some complex real world piece of software and having it work correctly the first time they get it to compile. Of course, many of them may not notice this right away because getting things to compile using Standard C++ may take more of an effort than they were originally use to. This is especially true when dealing with templates – the error messages can baffle the heck out of you. Nevertheless, those templates can do an awful lot for you.
The second thing I predict is that as more and more people actually start to develop real world applications using the Standard C++ library, there will be some percentage that discover that their version of the Standard C++ library is not adequate for their application. This should be a fairly obvious conclusion – "one size fits all" doesn’t work in software anymore than it does in other design arenas. Nevertheless, many people will find themselves rather annoyed when the solution their attempted solution turns out not to work very well. I know; I’ve been there.
This second prediction will be the basis for most of my columns in the near future. The general theme might be called "Using the Standard C++ library", but the subtitle might also be "What to do when things don’t go right". The Standard C++ Library is much more than just a big collection of classes that we might choose to use in our applications. First, and foremost, the Standard C++ Library is a set of abstractions. Obviously, we expect our vendors to provide reasonable implementations of those abstractions; and for the most part that is exactly what we will get. Unfortunately, a lot of developers want to throw out the abstraction itself, when it turns out that the implementations we have are not reasonable for a specific need. Much of what I will be showing is how to stay within the abstraction, but tailor the solution to better fit a specific need. Next time, I’ll start with some variations of the "string" class.
References
1. Reeves, J. "The (B)Leading Edge: Yet Another Visitor Pattern", The C++ Report, Vol. 10, No. 3, March 1998.
2. Reeves, J. "The (B)Leading Edge: Yet Another Visitor Pattern, part II", The C++ Report, Vol 10, No. 5, May 1998.
3. Gamma, E., et. al. Design Patterns: Elements of Reusable Object Oriented Software, Addison-Wesley, 1995.
4. Stroustrup, B. The Design and Evolution of C++, Addison-Wesley, 1994.
5. Meyers, S. More Effective C++, Addison-Wesley, 1994.
6. Reeves, J. "The (B)Leading Edge: Faking (and Exploring) Run-Time-Type-Information", The C++ Report, Vol. 9, No. 9, October 1997.
7. Vlissides, J. "Pattern Hatching: The Trouble with Observer", The C++ Report, Vol. 8, No. 7, September 1996.
8. Martin, R. "Acyclic Visitor" (submission to PloPD-96), see http://www.oma.com/PDF/acv.pdf.
9. Reeves, J. "The (B)Leading Edge: Low Overhead Class Design", The C++ Report, Vol. 10, No. 2, February 1998.
10. Reeves, J. "The (B)Leading Edge: Moving to Standard C++", The C++ Report, Vol. 9, No. 7, July/August 1997.
Figure 1.